
Retrouvez motrech sur son nouveau site http://motre.ch/
25 févr. 2005
J2J2 Brève - Retour vers le Passé...
En fouillant dans les archives de la liste motrech, voici ce que je découvre avec stupéfaction dans mon deuxième mail adressé à la liste, datant du 30 Juin 1998 (et oui, bientôt 7 ans déjà!):
Ca vous dit quelque chose?


Heu... non, avec ces photos là ce sera certainement plus facile...


Certainement déjà le début de ma "Google Addiction"...
Mais pourquoi n'ai-je pas été plus attentif à leurs travaux ????????
 Quoi qu'il en soit, on peut re-découvrir sur ce papier l'architecture générale de Google, qui n'a certainement pas beaucoup bougé 7 ans plus tard. Ainsi, on voit clairement, comme nous le pensions avec Jean Véronis qu'il y a deux bases de données: Le Repository qui contient les documents récupérés mais qui ne sont pas encore indexés, et les Barels qui contiennent les documents indexés. Ainsi, le nombre de pages indiqué dans les résultats de Google serait l'addition des documents du Repository et des Barels.
Quoi qu'il en soit, on peut re-découvrir sur ce papier l'architecture générale de Google, qui n'a certainement pas beaucoup bougé 7 ans plus tard. Ainsi, on voit clairement, comme nous le pensions avec Jean Véronis qu'il y a deux bases de données: Le Repository qui contient les documents récupérés mais qui ne sont pas encore indexés, et les Barels qui contiennent les documents indexés. Ainsi, le nombre de pages indiqué dans les résultats de Google serait l'addition des documents du Repository et des Barels.
Notons que c'est une architecture assez intuitive pour un moteur de recherche (pour qui souhaite un minimum parallèliser les tâches) qui pourrait aujourd'hui encore être utile à qui souhaiterais se lancer dans la grande aventure de la création d'un moteur...
Complément d'information apporté par Mathias Géry sur la liste motrech:

[...]
Pour commencer, je vous suggère une lecture très intéressante d'un papier
présenté à la 7ème conférence W3 (http://www7.conf.au/) qui c'est tenue à
Brisbane en Australie du 14 au 18 Avril 98 :
The Anatomy of a Large-Scale Hypertextual Web Search Engine - Sergey Brin,
Lawrence Page
http://www7.conf.au/programme/fullpapers/1921/com1921.htm
[...]
Note: Il semble que le serveur de la 7ème conférence W3 mentionné ci-dessus ne fonctionne pas. Vous pourrez cependant facilement retrouver cet article sur le Net, ou bien le récupérer ici.
Ca vous dit quelque chose?
Heu... non, avec ces photos là ce sera certainement plus facile...
Certainement déjà le début de ma "Google Addiction"...
Mais pourquoi n'ai-je pas été plus attentif à leurs travaux ????????
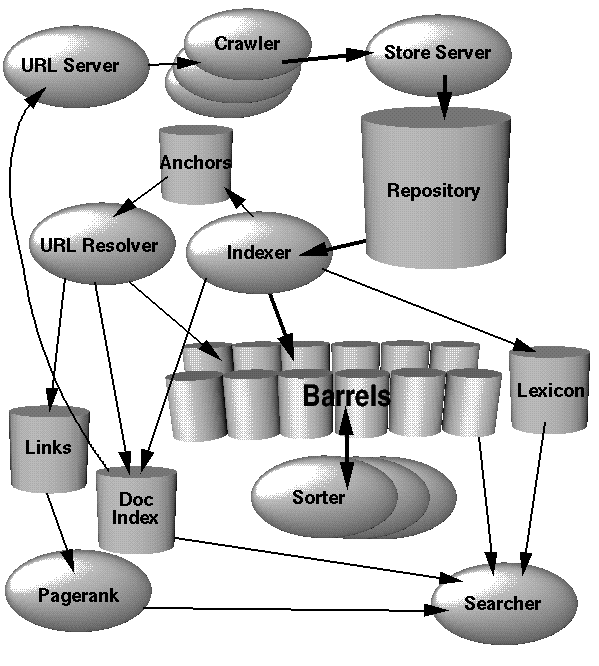 Quoi qu'il en soit, on peut re-découvrir sur ce papier l'architecture générale de Google, qui n'a certainement pas beaucoup bougé 7 ans plus tard. Ainsi, on voit clairement, comme nous le pensions avec Jean Véronis qu'il y a deux bases de données: Le Repository qui contient les documents récupérés mais qui ne sont pas encore indexés, et les Barels qui contiennent les documents indexés. Ainsi, le nombre de pages indiqué dans les résultats de Google serait l'addition des documents du Repository et des Barels.
Quoi qu'il en soit, on peut re-découvrir sur ce papier l'architecture générale de Google, qui n'a certainement pas beaucoup bougé 7 ans plus tard. Ainsi, on voit clairement, comme nous le pensions avec Jean Véronis qu'il y a deux bases de données: Le Repository qui contient les documents récupérés mais qui ne sont pas encore indexés, et les Barels qui contiennent les documents indexés. Ainsi, le nombre de pages indiqué dans les résultats de Google serait l'addition des documents du Repository et des Barels.Notons que c'est une architecture assez intuitive pour un moteur de recherche (pour qui souhaite un minimum parallèliser les tâches) qui pourrait aujourd'hui encore être utile à qui souhaiterais se lancer dans la grande aventure de la création d'un moteur...
Complément d'information apporté par Mathias Géry sur la liste motrech:
Pour poursuivre ce retour vers le passé : est-ce que vous avez utilisé google à l'époque stanford ?Et comme on peut le constater sur l'image ci-dessous, il y avait déjà l'esprit Google à l'époque...
Je crois bien que les pages ont disparu du web, par contre on peut les retrouver avec waybackmachine:
- l'interace d'interrogation de google en 98
- le matos de l'époque, qu'ils avaient récupéré à droite et à gauche

24 févr. 2005
J2J2 Motrech doped in Yahourts
This page has been automatically translated from French using Google language tools.
I did it! Proof with the support, here what you obtain with Google when you carry out a research on the terms " yahoo yahoourt ":

What a satisfaction! Me which announced in my very first ticket on this blog that it is it excel blog aixtal of Jean Véronis who had given me the desire for launching me in the adventure of the blog. And well now I exceed it... -)
But let us reconsider the facts. February 11, Jean Véronis publishes a ticket entitled " Lexicon: Yahoo and yahoourts "bearing on the research of the orthographies of the yahourt term on Yahoo . February 15, whereas I a ticket published on some tests of Y!Q , I found rather sympathetic to refer to the ticket of Jean Véronis by entitling mine "Test - Yahoo pedals in the yahoourt... ".
Several things however worry me on the result which I obtain:
- I use in my ticket the terms Yahoo 8 times , and Yahoourt 2 times .
- Jean Véronis uses the terms Yahoo 7 times and Yahoourt 3 times (more Yahoourts one time ).
- The frequency of use of the terms is rather in favour of Jean Véronis:
- Moreover, Jean Véronis in his ticket uses the lexical field abundantly referring to the lacteous products, whereas my ticket almost does not speak about it.
This classification in favour of my ticket would come it only from the title? My ticket is entitled "Test - Yahoo pedals in the yahoourt... " (yahoourt in the singular), whereas that of Jean Veronis is entitled " Lexicon: Yahoo and yahoourts "(yahoourt in the plural).
If such is the case, I council with engineers de Google to drop slightly (much?) the weighting granted to the title of a document, and more complex thing, to analyze the documents in their globality and not like a succession of terms to be indexed. By taking of account the lexical field of a document, and even that of the complete site, one would improve considerably the relevance of the results of the search engines.I thus benefit from it to reconsider the remarks of François Bourdoncle which had started some "sharp" reactions on the list motrech during its interview with 01.Net: " the technological war of the engines is finished ".
Once again, I will protest high and strong that NOT ! It seems to me far from being finished when I note such results on most popular of the search engines...
J2J2 Motrech dopé aux Yahourts
Je l'ai fait! Preuve à l'appui, voici ce que vous obtenez avec Google lorsque vous effectuez une recherche sur les termes "yahoo yahoourt":
Quelle satisfaction! Moi qui annonçais dans mon tout premier billet sur ce blog que c'est l'excellent blog aixtal de Jean Véronis qui m'avait donné l'envie de me lancer dans l'aventure du blog. Et bien maintenant je le dépasse... :-)
Mais revenons sur les faits. Le 11 Février, Jean Véronis publie un billet intitulé "Lexique: Yahoo et les yahoourts" portant sur la recherche des orthographes du terme yahourt sur Yahoo. Le 15 Février, alors que je publiait un billet sur quelques tests de Y!Q, j'ai trouvé plutôt sympa de faire référence au billet de Jean Véronis en intitulant le mien "Test - Yahoo pédale dans le yahoourt...".
Plusieurs choses m'inquiètent pourtant sur le résultat que j'obtiens:
- J'utilise dans mon billet les termes Yahoo 8 fois, et Yahoourt 2 fois.
- Jean Véronis utilise les termes Yahoo 7 fois et Yahoourt 3 fois (plus Yahoourts une fois).
- La fréquence d'utilisation des termes est plutôt en faveur de Jean Véronis:
- De plus, Jean Véronis dans son billet utilise abondamment le champ lexical faisant référence aux produits lactés, alors que mon billet n'en parle presque pas.
Ce classement en faveur de mon billet proviendrait-il uniquement du titre? Mon billet s'intitule "Test - Yahoo pédale dans le yahoourt..." (yahoourt au singulier), alors que celui de Jean Veronis s'intitule "Lexique: Yahoo et les yahoourts" (yahoourt au pluriel).
Si tel est le cas, je conseil aux ingénieurs de Google de baisser légèrement (beaucoup?) la pondération accordée au titre d'un document, et chose plus complexe, d'analyser les documents dans leur globalité et non comme une suite de termes à indexer. En prenant en compte le champ lexical d'un document, et même celui du site complet, on améliorerait considérablement la pertinence des résultats des moteurs de recherche.J'en profite donc pour revenir sur les propos de François Bourdoncle qui avaient déclenché quelques "vives" réactions sur la liste motrech lors de son interview à 01.Net: "La guerre technologique des moteurs est terminée".
Encore une fois, je vais clamer haut et fort que NON! Elle me semble loin d'être terminée lorsque je constate de tels résultats sur le plus populaire des moteurs de recherche...
15 févr. 2005
J2J2 Test - Yahoo pédale dans le yahoourt...
Après la lecture des deux billets élogieux "Y!Q : un outil contextuel étonnant et innovant !" (Abondance) et "Y!Q Search de Yahoo!" (Kesako ?) concernant le nouvel outil de Yahoo!, Y!Q Search, j'avais hâte de tester ce dernier.
Premier contact
Le premier contact est bien entendu la découverte de l'interface de recherche. Sobre, minimaliste, juste un champs de recherche, un logo et un bouton. Bref, une interface "à la Google". Parfait, on n'en demande pas plus à un moteur de recherche. Ce qui retient particulièrement mon attention, c'est l'habituel champs
INPUT (zone de saisie de texte simple, ne comportant qu'une ligne) utilisé dans la quasi-totalité des interfaces de recherche, remplacé ici par un TEXTAREA (zone de saisie de texte composée de plusieurs lignes). Yahoo! essayerait-il de me suggérer que je vais pouvoir effectuer des recherches en utilisant des requêtes complexes, de plus de deux ou trois mots, ou bien même en langage naturel?
Les premiers tests
Lors de mes premiers tests, tout comme mes deux accolites cités plus haut, je ne peux que constater, l'impression de pertinence des résultats obtenus.
Note: Je parlerais très certainement dans un prochain billet de la notion de pertinence, afin d'essayer de définir ce terme dans le contexte des moteurs de recherche sur Internet. Il est en effet relativement facile d'évaluer la pertinence d'un moteur de recherche sur un corpus fermé (comme lors des campagnes TREC - Text REtrieval Conference), mais sur un corpus ouvert comme le Web, quelles sont les méthodologies et les métriques à utiliser? Comment évaluer la pertinence d'un moteur de recherche sans pouvoir le mettre dans une boîte de Petri afin d'étudier son comportement dans un environnement clos?
Plusieurs choses m'inquiètent. Tout d'abord, le nombre de résultats est relativement faible. S'agit-il d'un outil disposant de sa propre base (indépendante de celle de Yahoo! et donc peut-être moins bien fournie dans ce cas), ou bien utilise-t-il la base de Yahoo!? Je fais donc quelques mesures rapides du nombre de résultats retournés par Y!Q et Yahoo!:
| Question | Nb. Docs. Y!Q | Nb Docs. Yahoo! |
|---|---|---|
| nombres premiers | 19 400 | 110 000 |
| motrech | 463 | 492 |
| vernis à ongles | 14 100 | 26 800 |
| technologies du langage | 789 | 251 000 |
Le constat est rapide, le nombre de documents réponse est largement plus faible sur Y!Q que sur Yahoo!. Mais à y regarder de plus prêt, il semble que cela ne soit pas vrai pour les interrogations uni-terme. Cela signifierait-il que la différence essentielle entre Y!Q et Yahoo! soit que le premier e recherche que l'expression exacte et non chacun des mots? Une deuxième expérience s'impose:
| Question | Nb. Docs. Y!Q | Nb Docs. Yahoo! |
|---|---|---|
| "nombres premiers" | 19 400 | 19 400 |
| "motrech" | 463 | 492 |
| "vernis à ongles" | 14 100 | 14 100 |
| "technologies du langage" | 780 | 734 |
Bon. Je crois que les choses sont claires sur ce point:
Les concepteurs de Y!Q se sont souvenu de ce que me répétait souvent mon directeur de thèse, Christian Fluhr (on n'écoute jamais assez ses maîtres!), concernant l'importance de la prise en compte des expressions composées et idiomatiques dans la pertinence d'un outil de recherche d'information.
Y!Q ne fait que rechercher l'expression exacte de la recherche
Pré-traitement de la requête
Là où Y!Q se distingue, c'est qu'il effectue un pré-traitement de la requête de recherche. En effet, il filtre la question pour en éliminer les termes inutiles (de manière parfois un peu cavalière comme vous le verrez ci-dessous), puis il découpe la requête en plusieurs sous-expressions (que par la suite, on peut sélectionner ou désélectionner pour changer le filtre de la recherche).
Par exemple, à partir de la requête "nombres premiers et technologies du langage dans les moteurs de recherche", voici ce que Y!Q propose comme thèmes de recherche:

Yahoo! n'est pas très "fair-play" avec Jean Véronis, qui pourtant l'a utilisé comme téléscope linguistique (cf commentaires) il n'y a pas très longtemps dans son très bon billet "Yahoo et les yahoourts", puisque l'air de rien, il élimine totalement la partie "technologies du langage" de la requête (tout comme il a éliminé les mots vides... sic!)
Essayons donc de pousser un peu plus les tests sur ce pré-traitement...
Si maintenant, j'effectue une recherche avec la requête: "les nombres premiers et les technologies du langage dans les moteurs de recherche" (j'ai juste rajouté les deux mots vides "les" en gras). Et bien, Y!Q revient sur son analyse précédente. Non pas que pour lui "technologies du langage" soit devenue une expression pertinente pour la recherche, mais finalement, comme j'ai maintenant trois fois le terme "les" dans ma question, Y!Q estime que ce terme doit certainement être pertinent pour ce que je cherche!
Si le nombre d'occurences des mots de la question a une importance dans le pré-traitement, je vais donc essayer de rajouter plusieurs occurences de l'expression "technologies du langage"...
Il faut que je rajoute deux occurences de cette expression (nous en avons donc maintenant trois) pour que Y!Q rajoute dans ma recherche le terme langage... poursuivons... je ne suis pas têtu (si?), mais je veux absolument qu'il retienne technologies du langage dans ses critères de recherche... il n'y a rien à faire, au bout de la quatrième occurence, le terme "les" disparaît (???) de la liste des expressions retenues pour la recherche, mais "technologies du langage" n'est toujours pas retenu,. Même avec plus d'une dizaine d'occurences dans la question je n'y parviens pas!
Je pense alors que l'expression "moteurs de recherche" est certainement trop "forte" par rapport aux autres expressions de la recherche. Je le supprime donc. Rien n'y fait, les "nombres premiers" écrasent largement les "technologies du langage"...
Même constat avec la question "les technologies du langage dans les moteurs de recherche", seuls les expressions "moteurs de recherche" et "les" sont retenues pour la recherche...
Dernier essai. Je capitule, et je lance une recherche avec uniquement "les technologies du langage", et toujours rien. Uniquement les deux termes "langage" et "les" sont retenus pour la recherche.
Y! regarder à deux fois...
Finalement, mes premières impressions de pertinence ont rapidement changé en impressions de "je comprends rien du tout à ce qu'il fait de mes requêtes ce @#!\%ù§& de Y!Q!!!!"
Au terme de cette première prise de contact, j'ai un peu de mal à être sensible à l'humour de Y!Q...

J2J2 Test - Yahoo pedals in the yahoourt...
This page has been automatically translated from French using Google language tools.
After the reading of two eulogistic tickets "Y!Q:a contextual tool astonishing and innovating! " (Abondance ) and " Y!Q Search de Yahoo! " ( Kesako? ) concerning the new tool of Yahoo! , Y!Q Search , I was in a hurry to test this last.
First contact
The first contact is of course the discovery of the interface of research. Sober, minimalist, just fields of research, a logo and a button. In short, an interface "à la Google " . Perfect, one does not ask any more one search engine. What holds my attention particularly, usual the fields
INPUT (zone of simple input of text, comprising only one line) used in the near total of the interfaces of research, replaced here by one TEXTAREA (zone of input of text made up of several lines). Yahoo! would it try me to suggest that I will be able to carry out research by using complex requests, of more than two or three words, or even in natural language ?First tests
During my first tests, just like my two accolites referred to above, I can only note, the impression of relevance of the results obtained.
Note: I would speak doubtless in a forthcoming ticket about the concept of relevance, in order to try to define this term in the context of the search engines on Internet. It is indeed relatively easy to evaluate the relevance of a search engine on a corpus closed (as at the time of campaigns TREC - T ext. RE trieval C are onference), but on an open corpus like the Web, which methodologies and the metric ones to use? How to evaluate the relevance of a search engine without being able to put it in a box of Cetri in order to study his behavior in a closed environment?
Several things worry me. First of all, the number of results is relatively weak . It is about a tool having its own base (independent of that of Yahoo! and thus perhaps less well provided in this case), or it uses the base of Yahoo! ? I thus make some fast measurements of the number of results turned over by Y!Q and Yahoo! :
| Question | Nb. Docs. Y!Q | Nb Docs. Yahoo! |
|---|---|---|
| prime numbers | 19 400 | 110 000 |
| motrech | 463 | 492 |
| nail varnish | 14 100 | 26 800 |
| technologies of the language | 789 | 251 000 |
The report is fast, the number of documents answer is largely weaker on Y!Q than on Yahoo! . But to look there of readier, it seems that that is not true for the stem interrogations. That would mean it that the essential difference between Y!Q and Yahoo! either what the first E seeks that the exact expression and not each word? A second experiment is essential:
| Question | Nb. Docs. Y!Q | Nb Docs. Yahoo! |
|---|---|---|
| "prime numbers" | 19 400 | 19 400 |
| "motrech" | 463 | 492 |
| "nail varnish" | 14 100 | 14 100 |
| "technologies of the language" | 780 | 734 |
Good. I believe that the things are clear on this point:
The originators of Y!Q remembered what often my reader repeated me, Christian Fluhr (one never listens to enough his Masters!), concerning the importance of the taking into account of the expressions made up and idiomatic in the relevance of a tool of search for information.
Y!Q does nothing but seek the exact expression of research
Preprocessing of the request
Where Y!Q is distinguished, it is that it carries out a preprocessing of the request of research. Indeed, it filters question from of to eliminate terms useless (in a way sometimes a little riding as you will see it below), then it cuts out the request in several under-expressions (that thereafter, one can select or désélectionner to change the filter of research).
For example, starting from the request "prime numbers and technologies of the language in the search engines" , here what Y!Q proposes like topics of research:
Yahoo! is not very "fair-play" with Jean Véronis , who however used as linguistic téléscope (cf comments ) it does not have there very a long time in his very good ticket " Yahoo and the yahoourts ", since the air of nothing, it completely eliminates the part "technologies of the language" from the request (just like he eliminated the blank words... sic!)
Thus let us try to push a little more the tests on this preprocessing...
So now, I carry out a research with the request: " prime numbers and technologies of the language in the search engines" (I just added the two blank words "" in fat). And well, Y!Q reconsiders its preceding analysis. Not how for him "technologies of the language" became a relevant expression for research, but finally, as I now have three times the term "them" in my question, Y!Q estimates that this term must certainly be relevant for what I seek!
If the number of events of the words of the question has an importance in the preprocessing, I thus will try to add several events of the expression "technologies of the language" ...
It is necessary that I add two events of this expression (we thus let us have now three of them) so that Y!Q adds in my research the language term ... continue... I am not obstinate (if?), but I want absolutely that there retains technologies of the language in its search criteria... it is not nothing to make, at the end of the fourth event, the term " them" disappears (???) from the list of the expressions retained for research, but "technologies of the language" is still not retained. Even with more than one ten events in the question I do not reach that point!
I think whereas the expression " search engines" is certainly too "strong" compared to the other expressions of research. I thus remove it. Nothing made there, the "prime numbers" largely crushes "technologies of the language" ...
Even report with the question "technologies of the language in the search engines" , only the expressions "search engines" and "them" are retained for research...
Last test. I capitulate, and I launch a research with only "technologies of the language" , and always nothing. Only the two terms "language" and "them" are retained for research.
Y! to look with twice...
Finally, my first impressions of relevance quickly changed into impressions of "I include/understand anything the whole so that it makes my requests this @#!\%ù§& of Y!Q !!!!"
At the end of this first making of contact, I have a little evil to be sensitive to the humour of Y!Q ...
12 févr. 2005
J2J2 Science - Do you habla französisch?
Dans un de ses précédents billets (je n'ai pas retrouvé lequel, malgrés mes lectures assidues), Jean Véronis parlait de la robustesse de l'indentification de la langue effectuée par Google. Plusieurs questions de posent alors à vos esprits attentifs:
Si ce genre de questions vous empêche chaque nuit de dormir, vous devriez aodrer ce qui va suivre...
Pour quoi faire?
Toute indexation efficace des documents textuels repose sur un minimum de traitements linguistiques. Or, tout traitement linguistique sur un texte est totalement dépendant de la langue de ce dernier. Il est donc essentiel dans un contexte multilingue tel que l’est par essence même Internet que les outils de recherche soient en mesure d’identifier automatiquement la langue des documents qu’ils sont amenés à traiter.
D'accord, et comment faire?
Essentiellement deux voies de recherche intéressantes concernent l’identification automatique de la langue des documents écrits.
La première, assez intuitive est appelée technique de reconnaissance des mots courts. Cette technique part du principe que les mots les plus communs d’une langue, tels que les conjonctions ou les propositions représentent de bon indices permettant de caractériser une langue.
La seconde technique, basée sur des fréquences des n-grams (séquence de
Vous m'en mettrez 3-grams s'il vous plait
La technique des n-grams a plusieurs avantages.
Tout d’abord, comme le montre [GrefenstetteG-95], si les deux méthodes sont aussi simples l’une que l’autre à implémenter, la technique des n-grams est plus stable, puisque comme l’illustre la figure suivante, ses performances se dégradent beaucoup moins que la technique des mots courts sur des phrases comportant peu de termes (en gris, un algorithme basé sur les mots courts, en noir sur les n-grams).
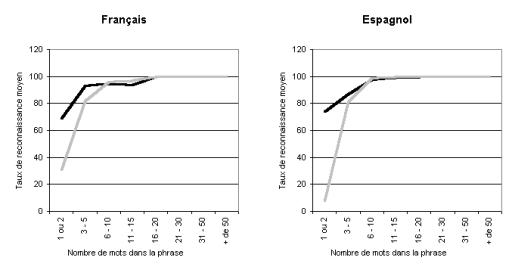
De plus, il s'avère qu'une implémentation basée sur les n-grams ne nécessite qu'un corpus d'entraînement relativement faible pour étalonner les fréquences de référence des différents n-grams. Expérimentalement, on peut établir qu'un corpus d'entrainement de l’ordre de quelques dizaines de Ko pour chaque langue permet déjà d’obtenir de bons résultats ([DunningT-94]).
J'ai testé pour vous
Comme le montrent les résultats de mes propres expérimentations sur la figure suivante, la convergence de l’algorithme est très rapide, puisqu’à partir d’environs

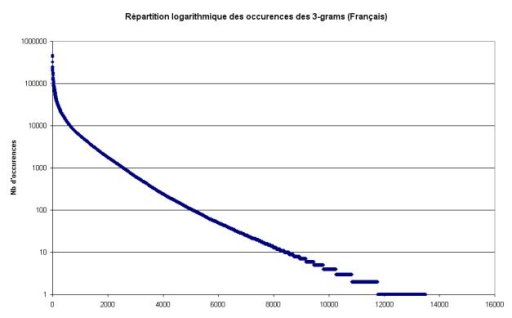
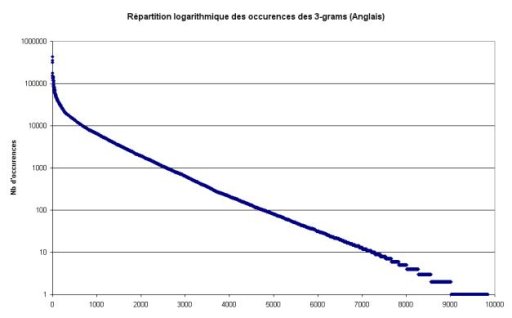
Nous pouvons facilement constater ce phénomène en étudiant la répartition des 3-grams en fonction de leur nombre d’occurrences dans le corpus analysé. Ainsi, comme le montrent les deux figure suivantes, correspondant respectivement au français et à l’anglais, un très faible nombre de 3-grams apparaît très fréquemment dans les textes analysés.
De la théorie à la pratique...
Ainsi, en se constituant un base de n-grams de référence pour chaque langue que l'on désire traiter, en prenant par exemple les 2000 ou 3000 n-grams les plus fréquents de chaque langue, on dispose d'un moyen simple et robuste pour identifier automatiquement la langue des documents. J'ai mené plusieurs expériences permettant même d'identifier de manière très nette les différentes langues d'un document multilingue.
Dans un prochain billet, je présenterais une librairie Java implémentant cette technique d'identification de la langue. Cette librairie sera bien entendu libre et j'en profiterais pour donner quelques mesures de performance de reconnaissance de la langue grâce à cette librairie.
[GrefenstetteG-95] Grefenstette Gregory. (1995), Comparing two language identification schemes, 3e Journées Internationales d'Analyse Statistique des Données Textuelles (JADT 95), pp. 263-268.
[DunningT-94] Dunning Ted (Mars 1994), Statistical Identification of Language, Technical Report, Computing Research Laboratory, New Mexico State University.
- Mais pourquoi identifier la langue?
- Et comment tout cela fonctionne-t-il?
Si ce genre de questions vous empêche chaque nuit de dormir, vous devriez aodrer ce qui va suivre...
Pour quoi faire?
Toute indexation efficace des documents textuels repose sur un minimum de traitements linguistiques. Or, tout traitement linguistique sur un texte est totalement dépendant de la langue de ce dernier. Il est donc essentiel dans un contexte multilingue tel que l’est par essence même Internet que les outils de recherche soient en mesure d’identifier automatiquement la langue des documents qu’ils sont amenés à traiter.
D'accord, et comment faire?
Essentiellement deux voies de recherche intéressantes concernent l’identification automatique de la langue des documents écrits.
La première, assez intuitive est appelée technique de reconnaissance des mots courts. Cette technique part du principe que les mots les plus communs d’une langue, tels que les conjonctions ou les propositions représentent de bon indices permettant de caractériser une langue.
La seconde technique, basée sur des fréquences des n-grams (séquence de
n caractères successifs) consiste à calculer pour chaque langue la fréquence d’apparition des séquences de n caractères dans un large corpus de texte. L’idée sous-jacente étant de considérer que par exemple un mot se terminant par la séquence -ck a de très fortes chances d’être un mot anglais, alors qu’un mot se terminant par -ez a beaucoup plus de chances d’être un mot français.Vous m'en mettrez 3-grams s'il vous plait
La technique des n-grams a plusieurs avantages.
Tout d’abord, comme le montre [GrefenstetteG-95], si les deux méthodes sont aussi simples l’une que l’autre à implémenter, la technique des n-grams est plus stable, puisque comme l’illustre la figure suivante, ses performances se dégradent beaucoup moins que la technique des mots courts sur des phrases comportant peu de termes (en gris, un algorithme basé sur les mots courts, en noir sur les n-grams).
De plus, il s'avère qu'une implémentation basée sur les n-grams ne nécessite qu'un corpus d'entraînement relativement faible pour étalonner les fréquences de référence des différents n-grams. Expérimentalement, on peut établir qu'un corpus d'entrainement de l’ordre de quelques dizaines de Ko pour chaque langue permet déjà d’obtenir de bons résultats ([DunningT-94]).
J'ai testé pour vous
Comme le montrent les résultats de mes propres expérimentations sur la figure suivante, la convergence de l’algorithme est très rapide, puisqu’à partir d’environs
2,5 Mo de données analysées, on peut considérer que la grande majorité des 3-grams significatifs de la langue ont étés rencontrés au moins une fois. Les nouveaux 3-grams qui apparaissent au delà de cette limite sont finalement relativement marginaux dans la langue. Certes, nous pourrions les considérer comme intéressants car discriminants, mais la probabilité de les rencontrer dans un texte est très faible. De plus, ces nouveaux 3-grams rencontrés au bout de plusieurs méga-octets de texte analysé correspondent pour la plupart à des noms propres, des abréviations, etc. et ne sont finalement pas représentatifs de la langue en question.Nous pouvons facilement constater ce phénomène en étudiant la répartition des 3-grams en fonction de leur nombre d’occurrences dans le corpus analysé. Ainsi, comme le montrent les deux figure suivantes, correspondant respectivement au français et à l’anglais, un très faible nombre de 3-grams apparaît très fréquemment dans les textes analysés.
De la théorie à la pratique...
Ainsi, en se constituant un base de n-grams de référence pour chaque langue que l'on désire traiter, en prenant par exemple les 2000 ou 3000 n-grams les plus fréquents de chaque langue, on dispose d'un moyen simple et robuste pour identifier automatiquement la langue des documents. J'ai mené plusieurs expériences permettant même d'identifier de manière très nette les différentes langues d'un document multilingue.
Dans un prochain billet, je présenterais une librairie Java implémentant cette technique d'identification de la langue. Cette librairie sera bien entendu libre et j'en profiterais pour donner quelques mesures de performance de reconnaissance de la langue grâce à cette librairie.
[GrefenstetteG-95] Grefenstette Gregory. (1995), Comparing two language identification schemes, 3e Journées Internationales d'Analyse Statistique des Données Textuelles (JADT 95), pp. 263-268.
[DunningT-94] Dunning Ted (Mars 1994), Statistical Identification of Language, Technical Report, Computing Research Laboratory, New Mexico State University.
11 févr. 2005
J2J2 Techno - Les entrailles de GoogleMaps
Si vous souhaitez en savoir un peu plus sur le fonctionne de Google Maps que je présentais dans un précédent billet, réjouissez vous!
En effet, Joel Webber, dans son blog, dissèque complètement le fonctionnement de Google Maps.
Attention cependant, si vous n'avez aucune idée de ce que signifient les acronymes Xml, Xsl, Url ou Http, passez votre chemin, et attendez mon prochain billet... ;-)
En effet, Joel Webber, dans son blog, dissèque complètement le fonctionnement de Google Maps.
Attention cependant, si vous n'avez aucune idée de ce que signifient les acronymes Xml, Xsl, Url ou Http, passez votre chemin, et attendez mon prochain billet... ;-)
J2J2 Info - WooglePedia
Un petit billet rapide pour une nouvelle toute chaude reprise par plusieurs blogs, dont Brian's reflexion ("Jimbo Wales meets with Sergey Brin and Larry Page").
La fondation Wikimedia est sur le point d'annoncer un accord avec Google. Les termes de cet accord ne sont pas encore publics ni complètement arrêtés.
Cependant, il semblerait que sans aucune contre partie de type GoogleAds, Google fournira à la fondation Wikimedia (qui lance des appels à votre bon coeur depuis quelques temps déjà) de la bande passante et des serveurs (car il est vrai que les serveurs de Wikimedia sont parfois un peu juste). En contre partie, la fondation Wikimedia mettra à la disposition de Google l'ensemble de son contenu.
Il est clair que cet accord a pour but de contrer le couple MSN Search/Encarta dont parlait justement Olivier Ertzscheid (Urfist Info) dans son billet de ce matin "Les projets de MSN".
La fondation Wikimedia est sur le point d'annoncer un accord avec Google. Les termes de cet accord ne sont pas encore publics ni complètement arrêtés.
Cependant, il semblerait que sans aucune contre partie de type GoogleAds, Google fournira à la fondation Wikimedia (qui lance des appels à votre bon coeur depuis quelques temps déjà) de la bande passante et des serveurs (car il est vrai que les serveurs de Wikimedia sont parfois un peu juste). En contre partie, la fondation Wikimedia mettra à la disposition de Google l'ensemble de son contenu.
Il est clair que cet accord a pour but de contrer le couple MSN Search/Encarta dont parlait justement Olivier Ertzscheid (Urfist Info) dans son billet de ce matin "Les projets de MSN".
8 févr. 2005
J2J2 Google via Michelin...
Décidément, le billet de Jean Véronis intitulé "à quoi ils marchent chez Google?" prend tout son sens ces derniers temps.
En effet, Google Maps est là! Et pour une version bêta, c'est impressionant! Les ViaMichelin et autres Mappy peuvent commencer à trembler...
Malheureusement pour nous, Français, et Européens ne sommes pour le moment pas concerné par Google Maps, seuls les Etats-Unis et le Canada sont intégrés dans Google Maps.
En revanche, le résultat est impressionnant, et comme je l'écrivais il y a quelques instants sur la liste motrech, les ingénieurs de chez Google n'ont font encore une démonstration de leur maîtrise du JavaScript et du DHTML. Comme pour GMail par exemple, ils savent trouver le bon compromis entre traitements côté client et traitements côté serveur afin de ne pas trop surcharger le client, tout en faisant un maximum de traitements côté client afin d'obtenir des temps de réponse extrêmement rapide, ce qui débouche sur une interface utilisateur très utilisable.
Lorsque vous arrivez sur Google Maps, une carte des Etats-Unis et du Canada s'affiche donc. Vous pouvez ensuite zoomer sur cette carte jusqu'à descendre au niveau des rues, mais aussi déplacer la carte de tous les côtés simplement en cliquant dessus et en faisant glisser la souris (des racourcis clavier sont également disponibles pour effectuer toutes ces actions).
Vous pouvez par la suite effectuer des recherches géographiques, ce qui aura pour effet de positionner la carte sur la zone recherchée. Vous pouvez par la suite, par exemple effectuer une recherche sur cette zone pour trouver des services locaux (cafés, restaurant, ...). Voici un petit exemple de recherche d'un café à Berkeley (remarquez l'ombre projetée du plus bel effet!!!)

Continuons maintenant notre exploration de cette version bêta et cliquons sur "To here" afin de savoir comment nous rendre au Jazz Cafe. Comme je suis actuellement domicilié à Sacramento, je saisis le nom de cette ville dans le champs qui s'affiche afin d'obtenir le trajet pour me rendre au Jazz Cafe qui m'a l'air de surcroit très sympathique... et quelques secondes plus tard...

J'obtiens mon itinéraire graphique accompagné de cette description détaillée...

Je peux enfin cliquer sur les différentes étapes de la description de l'itinéraire pour zoomer sur une partie particulière...
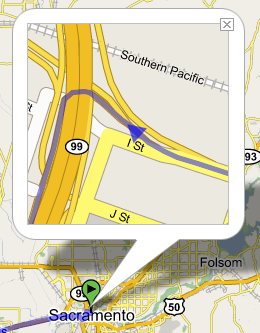
Je peux bien sûr à tout moment, imprimer la carte, l'envoyer par mail, ou bien sauvegarder l'URL de la carte (Google ferait il la promotion de l'architecture REST?)
En bref, encore un service Google très impressionnant, rapide, efficace, qui présente les choses non pas totalement différement de ses concurents, mais qui propose quelque chose de tout de même différenent et novateur. Du vrai Google quoi! Du Google pour me rendre encore un peu plus "Google Addicted" ...
<technorati>google map</technorati>
En effet, Google Maps est là! Et pour une version bêta, c'est impressionant! Les ViaMichelin et autres Mappy peuvent commencer à trembler...
Malheureusement pour nous, Français, et Européens ne sommes pour le moment pas concerné par Google Maps, seuls les Etats-Unis et le Canada sont intégrés dans Google Maps.
En revanche, le résultat est impressionnant, et comme je l'écrivais il y a quelques instants sur la liste motrech, les ingénieurs de chez Google n'ont font encore une démonstration de leur maîtrise du JavaScript et du DHTML. Comme pour GMail par exemple, ils savent trouver le bon compromis entre traitements côté client et traitements côté serveur afin de ne pas trop surcharger le client, tout en faisant un maximum de traitements côté client afin d'obtenir des temps de réponse extrêmement rapide, ce qui débouche sur une interface utilisateur très utilisable.
Lorsque vous arrivez sur Google Maps, une carte des Etats-Unis et du Canada s'affiche donc. Vous pouvez ensuite zoomer sur cette carte jusqu'à descendre au niveau des rues, mais aussi déplacer la carte de tous les côtés simplement en cliquant dessus et en faisant glisser la souris (des racourcis clavier sont également disponibles pour effectuer toutes ces actions).
Vous pouvez par la suite effectuer des recherches géographiques, ce qui aura pour effet de positionner la carte sur la zone recherchée. Vous pouvez par la suite, par exemple effectuer une recherche sur cette zone pour trouver des services locaux (cafés, restaurant, ...). Voici un petit exemple de recherche d'un café à Berkeley (remarquez l'ombre projetée du plus bel effet!!!)
Continuons maintenant notre exploration de cette version bêta et cliquons sur "To here" afin de savoir comment nous rendre au Jazz Cafe. Comme je suis actuellement domicilié à Sacramento, je saisis le nom de cette ville dans le champs qui s'affiche afin d'obtenir le trajet pour me rendre au Jazz Cafe qui m'a l'air de surcroit très sympathique... et quelques secondes plus tard...
J'obtiens mon itinéraire graphique accompagné de cette description détaillée...
Je peux enfin cliquer sur les différentes étapes de la description de l'itinéraire pour zoomer sur une partie particulière...
Je peux bien sûr à tout moment, imprimer la carte, l'envoyer par mail, ou bien sauvegarder l'URL de la carte (Google ferait il la promotion de l'architecture REST?)
En bref, encore un service Google très impressionnant, rapide, efficace, qui présente les choses non pas totalement différement de ses concurents, mais qui propose quelque chose de tout de même différenent et novateur. Du vrai Google quoi! Du Google pour me rendre encore un peu plus "Google Addicted" ...
MAJ 06/09/05 : "Walking on the Moon", "Godgle Attacks" et "Les entrailles de GoogleMaps".
<technorati>google map</technorati>
7 févr. 2005
J2J2 Godgle Addicted ?
Voilà qui commence bien! Dans mon précédent et premier billet de ce blog, je revendiquais de vouloir me forcer à rédiger des billets en français, et je poursuis avec ce billet dont le titre est un anglais. J'aurais pu certe nommer ce billet "Godgle Addiction?", mais j'ai une sainte horreur de cet anglicisme (Monsieur Véronis, rassurez moi, "addiction" est bien un anglicisme?).
J'ai pris aujourd'hui conscience à quel point le dieu Godgle comme aime à le nommé Jean Véronis (encore lui!) dans son blog Technologies du Langage prend une importance de plus en plus grande dans ma vie. A bien y réfléchir, je me demande si je ne suis pas en train de me faire doucement "Googliser" comme il le fut à une époque avec Micro$oft. Définitivement libéré de l'emprise de Billou après mon passage fort agréable à Linux (mon fils de 2 ans ne manque pas une occasion de faire "coin-coin" lorsqu'il voit Tux), je replonge immédiatement dans d'autres griffes... celles du dieu Godgle!
Je dresse un état de la situation: Pour effectuer des recherche sur le web, j'utilise par simplicité et certainement par fainéantise (endoctrinement?) quasiment exclusivement Google. Depuis un petit moment, tous mes mails sont sur GMail (d'ailleurs, si l'un d'entre vous a besoin d'une adresse GMail, j'ai une petite cinquantaine d'invitations dont je ne sais pas quoi faire). Il faut bien l'avouer, ce service de WebMail est bien pensé, dans une certaine mesure, il est innovant, et à l'usage, il est très très pratique! J'ai découvert il y a quelques semaines le logiciel Picasa 2, que j'ai tout de suite adopté pour la gestion de mes photos numériques personnelles, et devinez qui se cache derrière Picasa? Oui! Tout à fait, le dieu Godgle, encore lui... Et pour affirmer un peu plus ma "Googlance" (contraction de Google et dépendance), je créé ce blog sur Blogger, qui lui aussi est bien entendu "powered by Google"! J'allais oublié: je me suis également créé quelques alertes très ciblées sur Google Alerts afin de ne rien manquer (c'est un bien grand espoir, car je n'ai jamais décortiqué le sujet, mais Google Alert ne doit pas se baser sur un très grand nombre de résultats pour repérer les nouveautés!) de ces sujets.
Si je résume, ma porte d'accès sur le Web est "powered by Google", mes courriers électroniques sont "powered by Google", mes photos numériques sont "powered by Google", et mon carnet de voyage est "powered by Google" ...
Fort heureusement, mon passage à Linux ne me permet pas d'installer le Desktop Search de Google (qui n'est pas disponile pour cette plateforme), ni la Google Toolbar qui n'est disponible que pour les plateformes Micro$oft / Internet Explorer. Quant à Google Actualité, l'Annuaire Google, ou tous les autres services Google, je n'ai pas encore craqué car je trouve qu'il n'apportent rien de vraiment innovant (ou du moins qui réponde à mes besoins).
Après ce rapide état de ma catastrophique situation, je ne peux que mesurer l'importance de Google dans ma vie (la preuve en est d'ailleurs, je consacre un billet complet au dieu en question). Et je crois que la situation est encore plus terrible qu'il n'y paraît. En effet, en faisant une petite introspection personnelle, et en étant des plus honnêtes avec moi même, je crois même que j'en viens parfois à rêver que Google Print devienne une réalité, qu'il soit massivement déployé, que tous les contenus papier de la planète soient en pocession de Goggle et que je puisse ainsi avoir l'ensemble de la connaissance humaine à portée de clic...
Alors, oui, tout comme Jean Véronis, je m'interroge et me demande à quoi ils marchent chez Google, mais plus encore, je m'interroge sur les raisons de ma "Googlance"... En essayant de dominer un peu la toile grâce à des outils innovants, je me trouve prit doucement, insidieusement dans une autre toile qui se tisse jour après jour autour de chaucun d'entre nous, celle du World Wide Google...
Et vous, ou en êtes-vous avec Godgle ?

J'ai pris aujourd'hui conscience à quel point le dieu Godgle comme aime à le nommé Jean Véronis (encore lui!) dans son blog Technologies du Langage prend une importance de plus en plus grande dans ma vie. A bien y réfléchir, je me demande si je ne suis pas en train de me faire doucement "Googliser" comme il le fut à une époque avec Micro$oft. Définitivement libéré de l'emprise de Billou après mon passage fort agréable à Linux (mon fils de 2 ans ne manque pas une occasion de faire "coin-coin" lorsqu'il voit Tux), je replonge immédiatement dans d'autres griffes... celles du dieu Godgle!
{kind=link}
Je dresse un état de la situation: Pour effectuer des recherche sur le web, j'utilise par simplicité et certainement par fainéantise (endoctrinement?) quasiment exclusivement Google. Depuis un petit moment, tous mes mails sont sur GMail (d'ailleurs, si l'un d'entre vous a besoin d'une adresse GMail, j'ai une petite cinquantaine d'invitations dont je ne sais pas quoi faire). Il faut bien l'avouer, ce service de WebMail est bien pensé, dans une certaine mesure, il est innovant, et à l'usage, il est très très pratique! J'ai découvert il y a quelques semaines le logiciel Picasa 2, que j'ai tout de suite adopté pour la gestion de mes photos numériques personnelles, et devinez qui se cache derrière Picasa? Oui! Tout à fait, le dieu Godgle, encore lui... Et pour affirmer un peu plus ma "Googlance" (contraction de Google et dépendance), je créé ce blog sur Blogger, qui lui aussi est bien entendu "powered by Google"! J'allais oublié: je me suis également créé quelques alertes très ciblées sur Google Alerts afin de ne rien manquer (c'est un bien grand espoir, car je n'ai jamais décortiqué le sujet, mais Google Alert ne doit pas se baser sur un très grand nombre de résultats pour repérer les nouveautés!) de ces sujets.
Si je résume, ma porte d'accès sur le Web est "powered by Google", mes courriers électroniques sont "powered by Google", mes photos numériques sont "powered by Google", et mon carnet de voyage est "powered by Google" ...
{kind=link}
Fort heureusement, mon passage à Linux ne me permet pas d'installer le Desktop Search de Google (qui n'est pas disponile pour cette plateforme), ni la Google Toolbar qui n'est disponible que pour les plateformes Micro$oft / Internet Explorer. Quant à Google Actualité, l'Annuaire Google, ou tous les autres services Google, je n'ai pas encore craqué car je trouve qu'il n'apportent rien de vraiment innovant (ou du moins qui réponde à mes besoins).
Après ce rapide état de ma catastrophique situation, je ne peux que mesurer l'importance de Google dans ma vie (la preuve en est d'ailleurs, je consacre un billet complet au dieu en question). Et je crois que la situation est encore plus terrible qu'il n'y paraît. En effet, en faisant une petite introspection personnelle, et en étant des plus honnêtes avec moi même, je crois même que j'en viens parfois à rêver que Google Print devienne une réalité, qu'il soit massivement déployé, que tous les contenus papier de la planète soient en pocession de Goggle et que je puisse ainsi avoir l'ensemble de la connaissance humaine à portée de clic...
Alors, oui, tout comme Jean Véronis, je m'interroge et me demande à quoi ils marchent chez Google, mais plus encore, je m'interroge sur les raisons de ma "Googlance"... En essayant de dominer un peu la toile grâce à des outils innovants, je me trouve prit doucement, insidieusement dans une autre toile qui se tisse jour après jour autour de chaucun d'entre nous, celle du World Wide Google...
Et vous, ou en êtes-vous avec Godgle ?
6 févr. 2005
J2J2 Pourquoi un Blog?
Un Blog? Pourquoi donc un Blog? Il y a déjà un petit moment que cela me tente... sans pour autant trouver une réelle motivation.
Et puis, jour après jour, à la lecture des différents billets publiés sur le blog Technologies du Langage de Jean Véronis, il m'apparaissait de plus en plus évidant que je devait tenter l'aventure.
Différentes motivations donc à la création du blog motrech.
Tout d'abord, parler d'un sujet qui me tiens énormément à coeur, les moteurs de recherche.
Ce blog sera donc un moyen d'exprimer mes (quelques) idées sur le vaste et tumultueux monde des moteurs de recherche. Mais aussi un bloc note des nouvelles notables sur le domaine. Enfin, une extension logique au groupe de discussion motrech dont j'essayerais de synthétiser les interventions les plus marquantes et les sujets le plus "chauds"!
Ce blog sera aussi pour moi le moyen de faire l'exercice de me plier à la discipline d'écrire un billet au moins une fois par semaine dans un premier temps, et pourquoi pas quotidiennement un peu plus tard, lorsque la "mécanique" de la rédaction en français sera un peu moins rouillée (et oui, je travaille dans une société où tous les écrits se font en une espèce de "bouillie franglaise" qui, il me semble aurait tendance à me faire perdre tout réflexe d'écriture dans ma belle langue maternelle, le français. Quelqu'un a deviné de quelle société il s'agit?).
Enfin, j'espère aussi à travers ce blog, fournir des informations utiles à un certain nombre d'entre vous, et nouer de nombreux contacts avec les pationnés des moteurs de recherche. Vous que passez par ici, soyez donc les bienvenus!
Et puis, jour après jour, à la lecture des différents billets publiés sur le blog Technologies du Langage de Jean Véronis, il m'apparaissait de plus en plus évidant que je devait tenter l'aventure.
Différentes motivations donc à la création du blog motrech.
Tout d'abord, parler d'un sujet qui me tiens énormément à coeur, les moteurs de recherche.
Ce blog sera donc un moyen d'exprimer mes (quelques) idées sur le vaste et tumultueux monde des moteurs de recherche. Mais aussi un bloc note des nouvelles notables sur le domaine. Enfin, une extension logique au groupe de discussion motrech dont j'essayerais de synthétiser les interventions les plus marquantes et les sujets le plus "chauds"!
Ce blog sera aussi pour moi le moyen de faire l'exercice de me plier à la discipline d'écrire un billet au moins une fois par semaine dans un premier temps, et pourquoi pas quotidiennement un peu plus tard, lorsque la "mécanique" de la rédaction en français sera un peu moins rouillée (et oui, je travaille dans une société où tous les écrits se font en une espèce de "bouillie franglaise" qui, il me semble aurait tendance à me faire perdre tout réflexe d'écriture dans ma belle langue maternelle, le français. Quelqu'un a deviné de quelle société il s'agit?).
Enfin, j'espère aussi à travers ce blog, fournir des informations utiles à un certain nombre d'entre vous, et nouer de nombreux contacts avec les pationnés des moteurs de recherche. Vous que passez par ici, soyez donc les bienvenus!
Inscription à :
Articles (Atom)