
Retrouvez motrech sur son nouveau site http://motre.ch/
12 févr. 2005
J2J2 Science - Do you habla französisch?
Dans un de ses précédents billets (je n'ai pas retrouvé lequel, malgrés mes lectures assidues), Jean Véronis parlait de la robustesse de l'indentification de la langue effectuée par Google. Plusieurs questions de posent alors à vos esprits attentifs:
Si ce genre de questions vous empêche chaque nuit de dormir, vous devriez aodrer ce qui va suivre...
Pour quoi faire?
Toute indexation efficace des documents textuels repose sur un minimum de traitements linguistiques. Or, tout traitement linguistique sur un texte est totalement dépendant de la langue de ce dernier. Il est donc essentiel dans un contexte multilingue tel que l’est par essence même Internet que les outils de recherche soient en mesure d’identifier automatiquement la langue des documents qu’ils sont amenés à traiter.
D'accord, et comment faire?
Essentiellement deux voies de recherche intéressantes concernent l’identification automatique de la langue des documents écrits.
La première, assez intuitive est appelée technique de reconnaissance des mots courts. Cette technique part du principe que les mots les plus communs d’une langue, tels que les conjonctions ou les propositions représentent de bon indices permettant de caractériser une langue.
La seconde technique, basée sur des fréquences des n-grams (séquence de
Vous m'en mettrez 3-grams s'il vous plait
La technique des n-grams a plusieurs avantages.
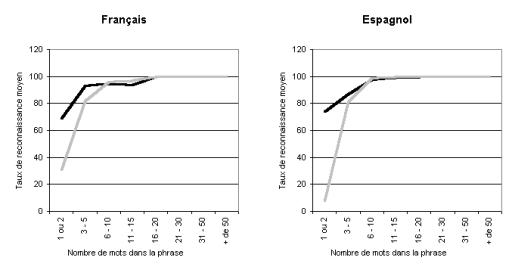
Tout d’abord, comme le montre [GrefenstetteG-95], si les deux méthodes sont aussi simples l’une que l’autre à implémenter, la technique des n-grams est plus stable, puisque comme l’illustre la figure suivante, ses performances se dégradent beaucoup moins que la technique des mots courts sur des phrases comportant peu de termes (en gris, un algorithme basé sur les mots courts, en noir sur les n-grams).
De plus, il s'avère qu'une implémentation basée sur les n-grams ne nécessite qu'un corpus d'entraînement relativement faible pour étalonner les fréquences de référence des différents n-grams. Expérimentalement, on peut établir qu'un corpus d'entrainement de l’ordre de quelques dizaines de Ko pour chaque langue permet déjà d’obtenir de bons résultats ([DunningT-94]).
J'ai testé pour vous
Comme le montrent les résultats de mes propres expérimentations sur la figure suivante, la convergence de l’algorithme est très rapide, puisqu’à partir d’environs

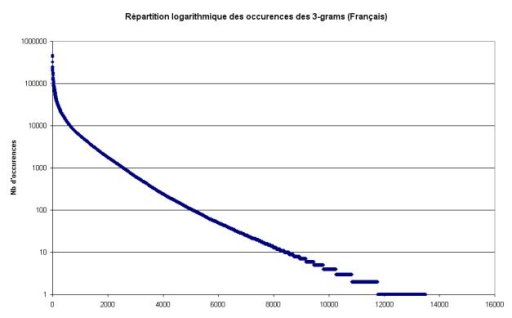
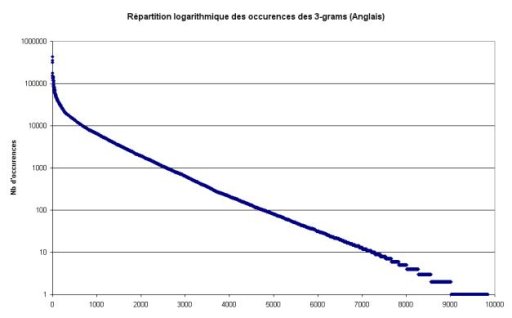
Nous pouvons facilement constater ce phénomène en étudiant la répartition des 3-grams en fonction de leur nombre d’occurrences dans le corpus analysé. Ainsi, comme le montrent les deux figure suivantes, correspondant respectivement au français et à l’anglais, un très faible nombre de 3-grams apparaît très fréquemment dans les textes analysés.
De la théorie à la pratique...
Ainsi, en se constituant un base de n-grams de référence pour chaque langue que l'on désire traiter, en prenant par exemple les 2000 ou 3000 n-grams les plus fréquents de chaque langue, on dispose d'un moyen simple et robuste pour identifier automatiquement la langue des documents. J'ai mené plusieurs expériences permettant même d'identifier de manière très nette les différentes langues d'un document multilingue.
Dans un prochain billet, je présenterais une librairie Java implémentant cette technique d'identification de la langue. Cette librairie sera bien entendu libre et j'en profiterais pour donner quelques mesures de performance de reconnaissance de la langue grâce à cette librairie.
[GrefenstetteG-95] Grefenstette Gregory. (1995), Comparing two language identification schemes, 3e Journées Internationales d'Analyse Statistique des Données Textuelles (JADT 95), pp. 263-268.
[DunningT-94] Dunning Ted (Mars 1994), Statistical Identification of Language, Technical Report, Computing Research Laboratory, New Mexico State University.
- Mais pourquoi identifier la langue?
- Et comment tout cela fonctionne-t-il?
Si ce genre de questions vous empêche chaque nuit de dormir, vous devriez aodrer ce qui va suivre...
Pour quoi faire?
Toute indexation efficace des documents textuels repose sur un minimum de traitements linguistiques. Or, tout traitement linguistique sur un texte est totalement dépendant de la langue de ce dernier. Il est donc essentiel dans un contexte multilingue tel que l’est par essence même Internet que les outils de recherche soient en mesure d’identifier automatiquement la langue des documents qu’ils sont amenés à traiter.
D'accord, et comment faire?
Essentiellement deux voies de recherche intéressantes concernent l’identification automatique de la langue des documents écrits.
La première, assez intuitive est appelée technique de reconnaissance des mots courts. Cette technique part du principe que les mots les plus communs d’une langue, tels que les conjonctions ou les propositions représentent de bon indices permettant de caractériser une langue.
La seconde technique, basée sur des fréquences des n-grams (séquence de
n caractères successifs) consiste à calculer pour chaque langue la fréquence d’apparition des séquences de n caractères dans un large corpus de texte. L’idée sous-jacente étant de considérer que par exemple un mot se terminant par la séquence -ck a de très fortes chances d’être un mot anglais, alors qu’un mot se terminant par -ez a beaucoup plus de chances d’être un mot français.Vous m'en mettrez 3-grams s'il vous plait
La technique des n-grams a plusieurs avantages.
Tout d’abord, comme le montre [GrefenstetteG-95], si les deux méthodes sont aussi simples l’une que l’autre à implémenter, la technique des n-grams est plus stable, puisque comme l’illustre la figure suivante, ses performances se dégradent beaucoup moins que la technique des mots courts sur des phrases comportant peu de termes (en gris, un algorithme basé sur les mots courts, en noir sur les n-grams).
De plus, il s'avère qu'une implémentation basée sur les n-grams ne nécessite qu'un corpus d'entraînement relativement faible pour étalonner les fréquences de référence des différents n-grams. Expérimentalement, on peut établir qu'un corpus d'entrainement de l’ordre de quelques dizaines de Ko pour chaque langue permet déjà d’obtenir de bons résultats ([DunningT-94]).
J'ai testé pour vous
Comme le montrent les résultats de mes propres expérimentations sur la figure suivante, la convergence de l’algorithme est très rapide, puisqu’à partir d’environs
2,5 Mo de données analysées, on peut considérer que la grande majorité des 3-grams significatifs de la langue ont étés rencontrés au moins une fois. Les nouveaux 3-grams qui apparaissent au delà de cette limite sont finalement relativement marginaux dans la langue. Certes, nous pourrions les considérer comme intéressants car discriminants, mais la probabilité de les rencontrer dans un texte est très faible. De plus, ces nouveaux 3-grams rencontrés au bout de plusieurs méga-octets de texte analysé correspondent pour la plupart à des noms propres, des abréviations, etc. et ne sont finalement pas représentatifs de la langue en question.Nous pouvons facilement constater ce phénomène en étudiant la répartition des 3-grams en fonction de leur nombre d’occurrences dans le corpus analysé. Ainsi, comme le montrent les deux figure suivantes, correspondant respectivement au français et à l’anglais, un très faible nombre de 3-grams apparaît très fréquemment dans les textes analysés.
De la théorie à la pratique...
Ainsi, en se constituant un base de n-grams de référence pour chaque langue que l'on désire traiter, en prenant par exemple les 2000 ou 3000 n-grams les plus fréquents de chaque langue, on dispose d'un moyen simple et robuste pour identifier automatiquement la langue des documents. J'ai mené plusieurs expériences permettant même d'identifier de manière très nette les différentes langues d'un document multilingue.
Dans un prochain billet, je présenterais une librairie Java implémentant cette technique d'identification de la langue. Cette librairie sera bien entendu libre et j'en profiterais pour donner quelques mesures de performance de reconnaissance de la langue grâce à cette librairie.
[GrefenstetteG-95] Grefenstette Gregory. (1995), Comparing two language identification schemes, 3e Journées Internationales d'Analyse Statistique des Données Textuelles (JADT 95), pp. 263-268.
[DunningT-94] Dunning Ted (Mars 1994), Statistical Identification of Language, Technical Report, Computing Research Laboratory, New Mexico State University.

Inscription à :
Publier les commentaires (Atom)
2 commentaires:
Belle étude. La loi de Zipf, une fois de plus... Vous connaissez le site de Gertjan van Noord ? Son logiciel TextCat est assez impressionnant (sources, démo en ligne).
Bien foutu indeed. D'ailleurs c'était à la suite d'une note de Jean que j'avais passé quelques heures à chercher de plus amples renseignements sur les méthodes de catégorisation de textes comme celles-ci. Le meilleur document de base, pour moi c'est le suivant (Cavnar et Trenkle): http://www.novodynamics.com/trenkle/papers/sdair-94-bc.pdf. J'ai commencé une
implémentation en java aussi. Mon idée était aussi d'essayer d'autres "distances" plutôt que la mesure "out-of-place". Mais j'ai pas le temps...
Enregistrer un commentaire