
Retrouvez motrech sur son nouveau site http://motre.ch/
18 nov. 2005
J2J2 Partitions pour Web 2.0 en la majeur
De nos tentatives de prospective lors de la journée "Peut-on vivre sans Google?", le clustering [en] est ressortit grand vainqueur.
Mais d'abord, c'est quoi le clustering?
Tout simplement (!?), une technique d'analyse statistique permettant de partitionner un ensemble de données en sous ensembles (les clusters). L'idée étant de regrouper les éléments partageant des traits communs ensembles. Selon la nature des données à traiter, ainsi que le résultat recherché, les critères de partitionnement seront bien entendu différents. Dans le domaine qui nous intéresse, celui du traitement du langage, il s'agira la plupart du temps de partitionner les documents en thèmes.Pourquoi le clustering va t'il se développer?
Les deux arguments essentiels laissant penser que l'utilisation du clustering devrait se répandre de plus en plus dans les outils de recherche sont:- Le clustering permet de présenter de manière synthétique les thèmes essentiels d'un large corpus de documents. Cette représentation permettant alors de naviguer dans le corpus de thèmes en sous-thèmes.
- Le clustering est aujourd'hui une technique éprouvée, qui a fait le tour d'un grand nombre de laboratoires de recherche et sur laquelle de très nombreux articles ont été publiés. La théorie est donc là, la technique aussi. Les nouveaux challenges du clustering, ceux qui lui permettront de séduire Madame Michu, sont essentiellement de trois ordres:
- Représentation graphique : Comment représenter au mieux les clusters d'un ensemble de documents?
- Navigation : Comment naviguer dans les clusters et sous-clusters?
- Intgration : Comment intégrer de manière intuitive et efficace la recherche par navigation dans les clusters et la recherche par mots clés?
meX-search
Mais d'autres solutions sont envisageables. Dans un mail intitulé "A search interface for the next generation?" [en], David Weiss nous en présentait hier matin une nouvelle sur la liste nutch-dev: meX-search. Basé sur les mêmes techniques de clustering que celles de nutch (carrot2), la représentation proposée par ce moteur est très intéressante: Simple, sobre, efficace et les clusters se sont montrés relativement pertinents lors de mes tests. Seuls petits points noirs : les animations qui à la longue deviennent pénibles (heureusement, elles sont désactivable), et le blondinet qui se ballade sur l'écran... peut-être que les filles aimeront... (Miss-TICS? Armelle?)
Vous trouverez donc ci-dessous quelques copies d'écran de meX-search que j'ai réalisé à partir de quelques recherches anodines. Chaque copie d'écran est accompagnée d'une représentation en nuage de mots afin que vous me donniez votre avis sur la pertinence de l'utilisation des nuages de mots pour représenter des clusters dans les résultats d'un moteur de recherche (j'ai arbitrairement choisi de faire pointer les liens des nuages de mots vers MozDex)...
"jerome charron" (aurais-je un problème avec mon égo?)
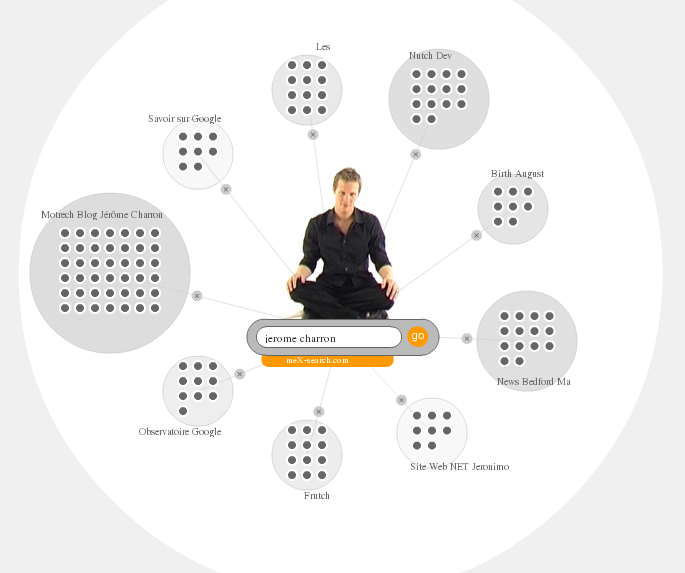
Birth August Frutch Les Motrech Blog Jérôme Charron News Bedford Ma Nutch Dev Observatoire Google Savoir sur Google Site Web NET Jeronimo
"motrech" (vous y êtes)
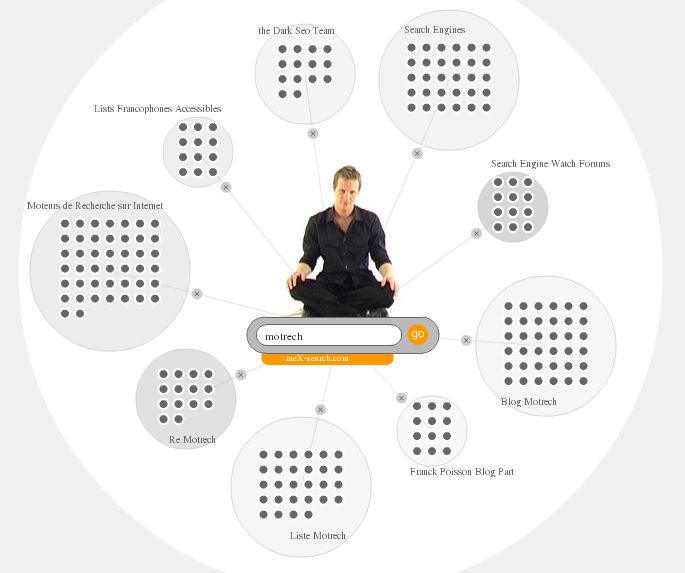
Blog Motrech Franck Poisson Blog Part Liste Motrech Francophones Accessibles Moteurs de Recherche sur Internet Re Motrech Search Engine Watch Forums Search Engines the Dark Seo Team
"nutch" (on ne se refait pas)

Built Ones Lucene Doug Cutting Index and Search Nutch Google Nutch Software Occupation Computing Related Internet Yahoo Nutch Open Source Search Engine Project Open-source Web Search Wikipedia the Free Encyclopedia
"les réacteurs à neutrons rapides" (une thèse au CEA, ça laisse des traces)
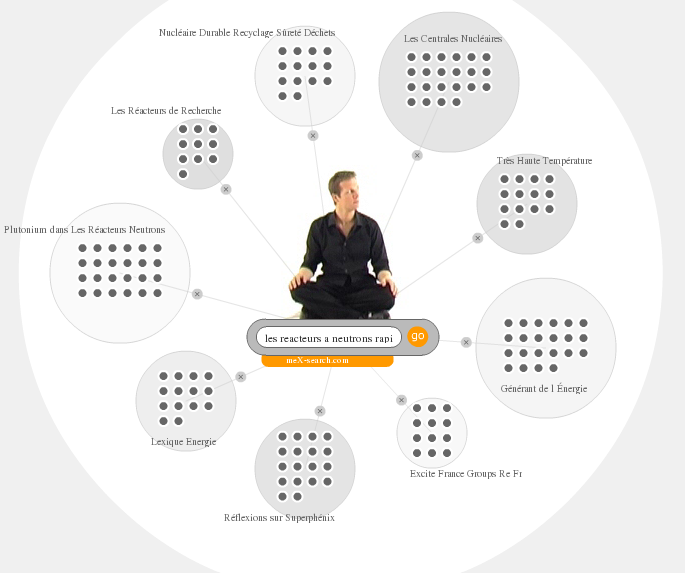
Plutonium dans Les Réacteurs Neutrons Les Réacteurs de Recherche Nucléaire Durable Recyclage Sûreté Déchets Les Centrales Nucléaires Très Haute Température Générant de l'Energie Excite France Groups Re Fr Réflexion sur Superphénix Lexique Energie
"jean véronis" (notre gourou à tous)

Nancy Ide and Jean Véronis Ratés dans les Moteurs Jean Francois Le Ny Jean Véronis Text Encoding Initiative Background and Context Google Indices Excite France Groups Re Fr Parallel Text Processing Linguist List Text Speech and Language Technology

Inscription à :
Publier les commentaires (Atom)
4 commentaires:
Merci pour ce post très intéressant et bien étayé. Mes premiers tests sur meX-search sont assez concluants en terme de pertinence, j'en suis même assez surprise (et c'est pas parce que je suis une fille que je ne trouve pas horripilant le blondinet qui se tourne les pouces à chaque requête...Encore que s'il y en a un différent à chaque recherche, je ne dis pas...bref, je m'égare...)
Tiens tiens, je vois que mon adaptation des TagClouds a plu. Pas mal le rouge, hein? ;-)
A part ça, je trouve meX-search très intéressant. Le clustering me semble être une voie incontournable (mais je suis un peu sceptique sur la vidéo, trop long, trop lourd).
Miss,
Je suis content de ne pas t'avoir déçu, toi qui attendais ce billet avec impatience.
Et un moteur de recherche à la mode calendrier Dieux du Stade, avec un nouveau musclé différent tous les jours... non?
Jean,
Dans un draft de ce billet il y avait un remerciement pour le pompage du css tagcloud, et puis comme j'avais déjà pas mal linké sur aixtal, et qu'en plus ce css est très peu différent de celui d'origine de tagcloud, je l'ai finalement retiré.
Désolé d'avoir dévoilé au grand jour Nancy Ide and Jean Véronis...
Clouds: Pas de problème! J'ai juste ajouté deux niveaux: le niveau 10 que j'utilise pour marquer le mot le plus fréquent du nuage, car je trouve qu'il faut le faire ressortir plus nettement, et le niveau 0, quasiment illisible (volontairement) mais que je n'utilise pas systématiquement (uniquement pour montrer que certains mots sont absents par exemple).
Nancy Ide: Normal, ça reflète mon travail aux Etats-Unis et une longue collaboration. Plus bizarre, Jean-François le Ny. Je le connais, mais n'ai jamais vraiment travaillé avec lui. Ca illustre un peu mon sentiment sur ce type de clusters: le système de représentation est très intéressant, mais le clustering proprement dit qui est derrière n'est pas très bon (j'ai un peu le même sentiment sur des outils comme Kartoo). Exalead a fait beaucoup de progrès, par exemple, sur la question des termes associés (qui fait de facto une sorte de clustering), alors qu'il y a quelques mois c'était encore assez bruité. Ca a tout changé. Leur système est passé d'inutilisable à très pertinent. C'est que qui manque à meX-search...
Au fait meX-search ne donne pas la même chose avec "jean veronis" entre guillemets (c'est un peu plus pertinent avec il me semble).
Enregistrer un commentaire